엘라스틱서치 이해하기
- 코딩/ElasticSearch
- 2025. 3. 26.
개인적으로 사이드 프로젝트 진행중 10억개의 데이터를 저장하고 조회를 할일이 생겨 세팅부터 운영을하며 새로 알게된 내용을 기록할 예정입니다.
우선 사용하지 않는 윈도우 PC를 사용해 온프레미스 환경에서 구축하며, 트래픽이 많지 않고 4개의 인덱스이기 때문에 Single Node에 1개의 샤드로 구성해보려고한다. (이후에 레플리카 샤드나 샤드추가) 생각해보니 온프레미스라 PC1대니까 무조건 싱글노드인데 그럼 온프레미스에서 멀티노드를 사용하려면 앞단에 nginx 웹서버를 두고 로드밸런싱을 해야하나...
1. Elasticsearch란?
Elasticsearch는 분산 검색 및 분석 엔진으로, 대용량의 데이터를 빠르게 검색하거나 통계를 낼 때 주로 사용
로그 수집, 상품 검색, 자동완성, 추천 시스템 등 다양한 곳에서 사용될 것 같다.
2. 핵심 개념 요약
| 클러스터 | 여러 노드가 모여서 하나의 시스템처럼 작동하는 집합 | 회사 전체 |
| 노드(Node) | Elasticsearch 인스턴스 (1개의 서버) | 직원 1명 |
| 샤드(Shard) | 데이터를 나누는 단위 (데이터 분산 저장) | 일거리(업무 단위) |
| 레플리카 샤드 | 샤드의 복제본 (읽기 부하 분산 및 장애 복구용) (DB에서 리플리케이션과 유사) | 백업직원 |
| 인덱스(Index) | 논리적인 데이터 단위 (DB에서의 데이터베이스) | 프로젝트 명 (테이블) |
| 도큐먼트(Document) | 실제 저장되는 JSON 데이터 (DB에서 row 데이터) | 한 줄 데이터 |
| 필드(Field) | 도큐먼트 내부의 속성 (DB의 컬럼) | 속성 정보 |
- 인덱스에 데이터 넣는걸 인덱싱 즉 색인이라고 한다. 네이버 서치어드바이저나 구글 서치콘솔에서 색인 하는게 이거 같다.
3. Elasticsearch 작동 구조
- 클러스터는 여러 노드로 구성됨 (싱글로도 가능)
- 하나의 인덱스는 여러 샤드로 나눠짐 (싱글로도 가능)
- 샤드는 각각 다른 노드에 분산 저장됨 (데이터 분산 저장 - rdb에 1억건의 데이터가 있고 샤드가 5개 있다면 2천건씩)
- 검색 쿼리를 보내면, 모든 샤드에서 병렬로 처리 → 성능 향상
- 레플리카 샤드는 읽기 부하를 분산하고, 장애 시 복구 역할도 수행함
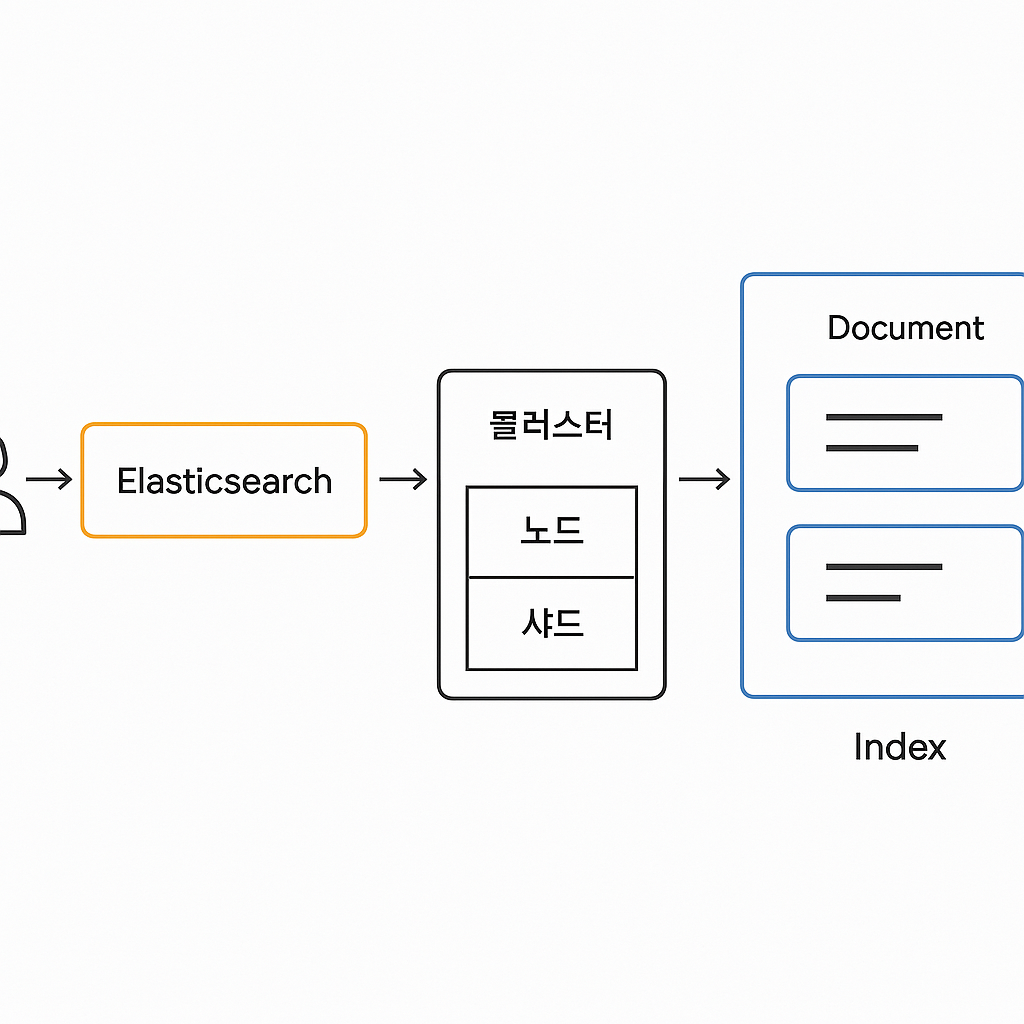
4.Elasticsearch vs. RDB 개념 정리
| 클러스터 | 여러 노드로 구성된 전체 시스템 | DB 서버 여러 대 |
| 노드 | 클러스터 내 하나의 서버 | 단일 DB 서버 |
| 인덱스 (Index) | 도큐먼트들을 저장하는 공간 (관계형 DB의 테이블에 가장 가까움) | 테이블 (Table) |
| 타입 (Type) | 예전에는 인덱스 내에 여러 타입 가능했지만, 이제는 단일 타입만 사용 | 테이블 스키마 내 다른 row 유형 |
| 도큐먼트 (Document) | 실제 데이터 (JSON 형식) | 행(Row) |
| 필드 (Field) | 도큐먼트의 속성 | 열(Column) |
5. Analyzer (분석기)
- 데이터를 저장하거나 검색할 때 텍스트를 어떻게 나눌지 정의하는 도구
- 한국어 검색 시 nori 분석기가 자주 사용됨 (필자는 nori를 사용해보고자 한다.)
- _analyze API를 통해 결과 확인 가능
POST /_analyze
{
"analyzer": "nori",
"text": "대한민국의 수도는 서울입니다."
}
{
"tokens": [
{
"token": "대한민국",
"start_offset": 0,
"end_offset": 4,
"type": "word",
"position": 0
},
{
"token": "수도",
"start_offset": 7,
"end_offset": 9,
"type": "word",
"position": 1
},
{
"token": "서울",
"start_offset": 10,
"end_offset": 12,
"type": "word",
"position": 2
}
]
}"대한민국의 수도는 서울입니다."는 nori 분석기에 의해 "대한민국", "수도", "서울" 같은 유의미한 형태소 단위로 나뉘어 저장되는걸 볼수있다.
6. Query DSL 예시
{
"query": {
"match": {
"keyword": {
"query": "아이폰 케이스",
"operator": "and"
}
}
}
}Elasticsearch는 JSON 기반 쿼리 언어를 사용하며, match, term, range, bool 등의 조건들을 조합해 검색이 가능하다.
7. 운영 고려 포인트
✅ 레플리카 샤드
- 읽기 성능 향상
- 장애 복구 대비
- 노드가 2개 이상일 때만 의미 있음
✅ 샤드
- 데이터 분산 저장
- 병렬 처리로 검색 속도 향상
- 너무 많으면 오히려 느려짐 (권장: 샤드당 10~30GB)
✅ 노드
- 트래픽/데이터 증가 시 수평 확장
- 리소스 (RAM, CPU, Disk)에 맞춰 점진적 확장
8. 확장 전략
| 읽기 부하 많음 | ✅ 레플리카 추가 + 노드 확장 |
| 쓰기 부하 많음 | ✅ 샤드 수 조절 + 노드 확장 |
| 고가용성 필요 | ✅ 레플리카 샤드 필수 |
| 데이터 크기 증가 | ✅ 샤드 분할 또는 인덱스 롤오버 |
다음편은 엘라스틱 설치 과정 및 새로 알게된 내용을 적어보려고한다.
'코딩 > ElasticSearch' 카테고리의 다른 글
| 엘라스틱서치 설치 및 기본내용 (0) | 2025.03.26 |
|---|---|
| SpringBoot + ElasticSearch 연동 및 간단 API 호출해보기 (0) | 2022.11.02 |
| 엘라스틱서치 매핑 (0) | 2022.11.02 |
| 엘라스틱서치 검색 방법 (URI, Request Body) (0) | 2022.05.14 |
| [Elasticsearch]엘라스틱서치의 기본개념 및 장점/단점 (0) | 2022.05.14 |